You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the company’s data privacy regulations and the users who executed the queues.
Which two components should you include in the solution? Each correct answer presents
part of the solution. NOTE: Each correct selection is worth one point.
A . sensitivity-classification labels applied to columns that contain confidential information
B . resource tags for databases that contain confidential information
C . audit logs sent to a Log Analytics workspace
D . dynamic data masking for columns that contain confidential information
Answer: A,C
Explanation:
A: You can classify columns manually, as an alternative or in addition to the recommendation-based classification:
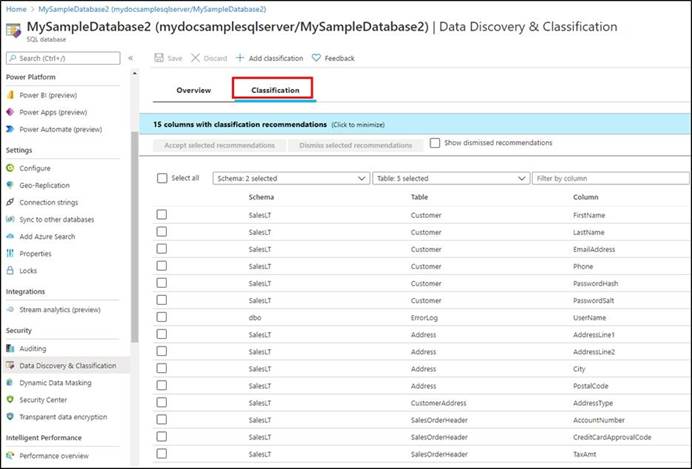
✑ Select Add classification in the top menu of the pane.
✑ In the context window that opens, select the schema, table, and column that you want to classify, and the information type and sensitivity label.
✑ Select Add classification at the bottom of the context window.
C: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field logs the sensitivity classifications (labels) of the data that was returned by a query. Here’s an example:

Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/data-discovery-and-classification-overview