Topic 6, Tailspin Toys Case B
Overview
Tailspin Toys is a manufacturing company that has offices across the United States, Europe, and Asia.
Tailspin Toys plans to implement a business intelligence (BI) solution for its US-based headquarters to manage the sales data, including information on customer transactions, products, sales quotas, and bonuses.
Existing Environment
Data Sources
Tailspin Toys currently stores data in line-of-business applications, relational databases, flat files, and the following;
– A Microsoft Excel spreadsheet named MarketResearch.xlsx. The spreadsheet is stored on a network drive in a directory owned by an analyst.
– A tabular model named Research.xlsx used in PowerPivot for Excel. Research.xlsx uses MarketResearch.xlsx as one of its data sources.
Network
The network contains an Active Directory forest named tailspintoys.com. The forest contains a Microsoft SharePoint Server 2013 server farm.
Implementation Plans
Databases
Tailspin Toys plans to build a star schema data warehouse named DB1. DB1 will be loaded from several different sources and will be updated nightly to contain new sales data.
DB1 will contain the following table types:
– A fact table to store transactional data, including transaction date, productID, customerID, quantity, and sales amounts.
– Dimension tables to store information about each customer, each product, each date, and each sales department user.
BI Semantic Models
Tailspin Toys plans to deploy the following BI semantic models:
– A multidimensional cube named CUBE1 that will store sales data. CUBE1 will be based on DB1 and will be hosted in SQL Server Analysis Services (SSAS). CUBE1 will contain two distinct count measures named Unique Customers and Unique Products. The measures are expected to aggregate hundreds of millions of rows from DB1.
– A tabular model named Sales Commission that will contain information about sales department user quotas and commissions.
– A tabular model named Research that will contain the migrated model from Research.xlsx.
– An instance of SSAS in tabular mode named Tabular.
Planned Reports and Queries
Tailspin Toys plans to implement the following reports and queries:
– Power View reports that use data from the Research model.
– Reports for each year the company recorded sales data that used the Sales Commission model. The reports will use the Dates_Between () and the DatesInPeriod () DAX functions in queries.
– Reports that use CUBE1 that contain the following query statements:
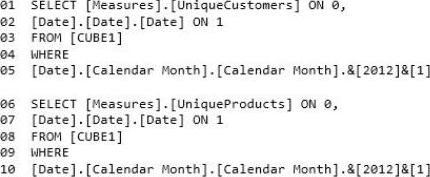
– A report named SalesByCategory that uses CUBE1 and the following query statement: (Line numbers are included for reference only.)
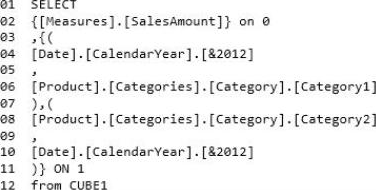
Self-Service Reporting
Tailspin Toys plans to deploy the following self-service reports:
– Reports created by sales department specialists that use CUBE1 and contain drillthroughs, maps, sparklines, and Key Performance Indicators (KPIs). The reports will be stored in a SharePoint Server document library named Library1.
– Reports created by sales department managers that use the Sales Commission model. The reports will contain visualizations that show sales department users their current sales as compared to their quota.
– Power Pivot models stored in a SharePoint Server document library that is configured as a PowerPivot Gallery named Gallery1.
Requirements
Data Security Requirements
Sales department users browsing CUBE1 must be able to view the sales data that relates to their respective customers only.
Access to reports must be controlled by using SharePoint permissions.
ETL Requirements
Tailspin Toys identifies the following extract, transformation, and load (ETL) requirements:
– Nightly updates of DB1 must support the incremental load of dimension and fact tables on separate schedules. Fact data may be loaded before dimension data.
– ETL processes must be able to update dimension attributes without losing context for historical facts.
– Referential integrity between dimension and fact tables must be maintained at all times.
Cube Performance Requirements
The design of CUBE1 must minimize the processing time of the UniqueCustomers and Unique Products measures. The time required to process CUBE1 each night must be minimized.
Data Refresh Requirements
The Research model must be refreshed nightly without interrupting the workflow of the analyst.
You need to recommend a cube architecture for CUBE1. The solution must meet the performance requirements for CUBE1.
Which two partitions should you recommend creating? Each correct answer presents part of the solution.
A . Partitions based on the values of the customerID column in the dimension table
B . Partitions based on the values of the customerID column in the fact table
C . Partitions based on the values of the productID column in the fact table
D . Partitions based on the values of the productID column in the dimension table
Answer: A, D